Zipf's Law in the Book
A quick experiment: plot the word frequencies of The Math Inside the Machine and watch Zipf's law emerge.
In the opening chapter of The Math Inside the Machine, I pause on a strange universality: Zipf’s law. Rank the words in a language by frequency, plot rank versus count on log-log axes, and the points collapse into a straight line. It looks like a law, even though no one designed it.
So I asked the obvious question: does the book itself obey the pattern it describes?
I extracted the text from the manuscript PDF, normalized the words, and counted the results. The book contains 59,943 word tokens and 6,973 unique words. When you plot the distribution, the line appears exactly where it should.
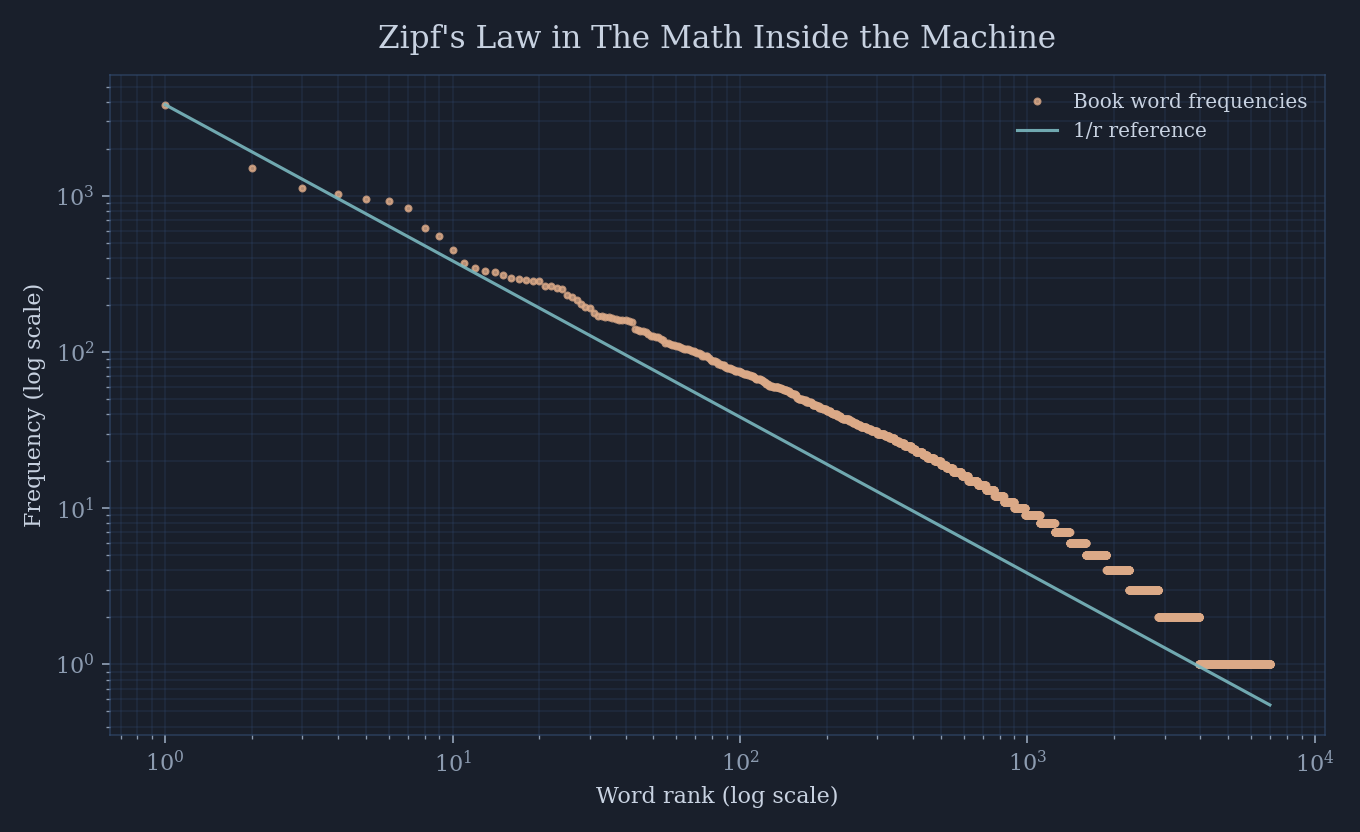
A few concrete numbers make the shape feel real. The most common word is the at 3,835 mentions - about 6.4% of the entire book. The drop-off is sharp, and the long tail is long.
Why Zipf Keeps Appearing
In the book, Zipf’s law shows up as another universal structure - like the golden angle or Benford’s law - patterns that surface whenever counting rubs against efficiency. Language is a compression system. We re-use short words for common ideas and reserve longer words for rarities. The distribution is an emergent consequence of people trying to communicate with minimal effort.
What’s striking is that this book, written by a human about mathematics, still inherits that same statistical skeleton. You can see the curve bend the same way it bends for English in general. The story carries new ideas, but the grammar of frequency stays the same.
The Book’s Own Zipf Line
This plot is built directly from the manuscript itself. It’s the same book that explains Zipf’s law now serving as its own data set. That self-reference felt too good not to visualize.
If you want the full discussion - why the law is so tight, why tokenizers rediscover it, and what it implies for AI - it’s in Chapter 1, right after the golden angle detour.